


Vector Databases: The Most Trending Technology Right Now .
What is vector databases and how it is growing in terms of usage in recent days?


A vector database is a type of database that stores and manages unstructured data, such as text, images, or audio, in vector embeddings (high-dimensional vectors) to make it easy to find and retrieve similar objects quickly.
Vector embeddings are mathematical representations of features or attributes that are used to represent the meaning of data. They are typically created using machine learning models, and they can be used to represent a wide variety of data, including text, images, and audio
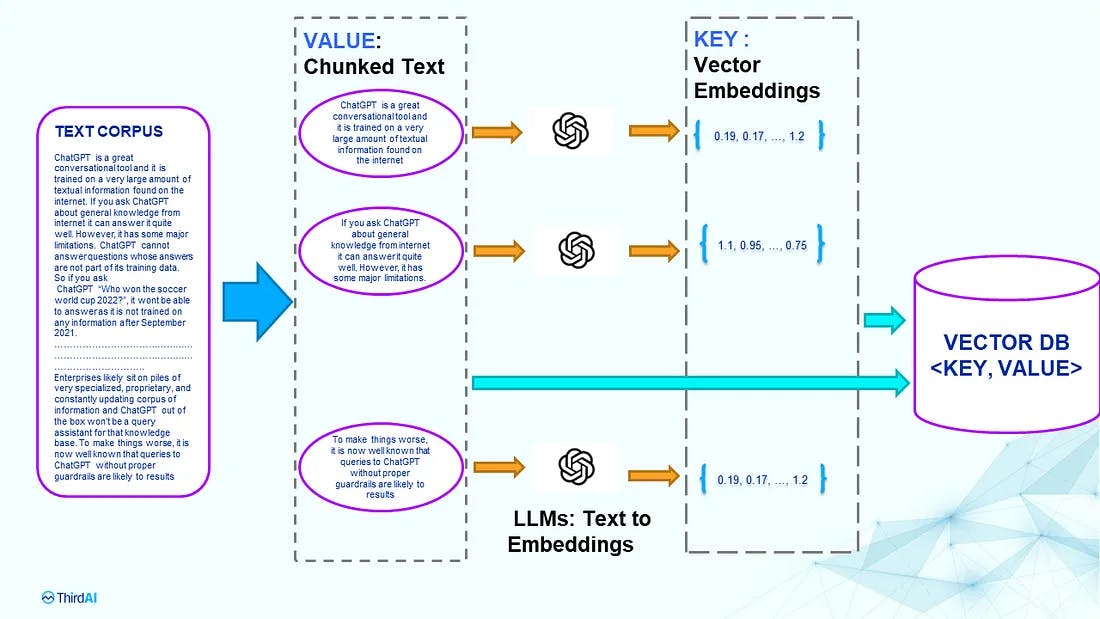
The image above depicts a diagrammatical representation of the functioning of vector databases.
Explanation of the Diagram:
Firstly, you can observe that a substantial amount of data is provided as input. This input data is subsequently divided into smaller chunks, facilitating seamless execution of functions.
Secondly, a Large Language Model (LLM) is utilized to convert the data into vectors. A vector, in this context, is an array of numbers wherein each element signifies a distinct dimension of the data. These dimensions can be envisioned as specific properties of the data, generated or interpreted by the employed LLM.
Thirdly, the vector database stores these vectors using indexing, thereby enabling rapid searches. Each vector functions as a key associated with a value, wherein the value represents the data stored within the database. This approach expedites the search process even for unstructured data types like images, audio files, videos, etc. Such data can be compared with the query output based on the presence of vectors in the database that match the vectors of the query.
Why there is a need of vector databases in AI-related applications?
"Over 80% of the data on the internet is unstructured, which includes audio, videos, text, and images. This unstructured data cannot be easily accommodated within relational databases. For instance, when a customer provides reviews, it's challenging to establish a direct relationship with the corresponding product and the sentiment of the customer during the review. Finding connections in such cases becomes difficult. However, we can instead search for specific identifiers within the text provided by the user in their review to transform data into meaningful information.
Similarly, when employing AI, it can generate extensive text or the data might be presented in formats like PDF or Word Excel, which could be quite distinct. Relating these disparate pieces of information can be an intricate task. In such scenarios, we need to explore more effective approaches to extract valuable insights and serve our objectives. This is where vector databases come into play. They offer innovative ways to organize, search, and analyze unstructured data, helping us derive meaningful results from diverse sources."
Vector Database Advantages:
Scalability: The biggest is the scalability of data. We will be storing Vector embeddings, which are a huge set of numerical values each value representing dimension of that particular object, We will be using indexing for faster searches.
Flexibility: They can store and query data in a variety of formats. They can be used for a variety of applications. They can be scaled to meet the needs of your application.
Fast similarity search and Accuracy: Vector databases are designed to efficiently store and query vector embeddings. This makes them well-suited for applications that require fast similarity search, such as recommendation systems, image search, and natural language processing.
Unstructured data: It makes it easy to work on large unstructured data.
Few Vector Db’s
PINECONE:
From Blog of Pinecone Gibbs Gullen (Senior marketing managerPinecone)-
Launched: Pinecone was introduced in 2021 (almost 2 years old now). At the onset of 2022, we found it necessary to make certain adjustments to keep pace with our rapidly expanding user community. And that's exactly what we did – commencing with a notable Series A funding round of $28M announced in March.
Since then, we've been consistently monitoring the adoption of vector search across a range of applications and emerging use cases. Presently, Pinecone has found traction among esteemed clients such as Workday, Mem, Clubhouse, BambooHR, Expel, and numerous others. They leverage Pinecone for diverse purposes including semantic search, anomaly detection, recommendation systems, multi-modal search, fraud detection, and more.
About customers Workday: Workday, Inc., is an American on‑demand (cloud-based) financial management, human capital management, and student information system software vendor. Total assets: over 1 billion dollars. Number of employees 17,700 (January 2023) - In 2022, we attended and sponsored several conferences, including Southern Data Science Conference, SIGIR
Features
Pinecone serves as a cloud-based vector database, presenting an array of features and advantages to the infrastructure community:
Fast and Fresh Vector Search: Pinecone ensures ultra-low query latency, even when dealing with massive datasets. This means users consistently enjoy an exceptional experience, irrespective of the dataset size. Moreover, Pinecone's indexes receive real-time updates, guaranteeing users access to the most current information.
Filtered Vector Search: Pinecone allows the fusion of vector search with metadata filters to yield more pertinent and swift results. For instance, you can employ filters based on product category, price, or customer rating.
Real-time Updates: Pinecone supports dynamic data updates in real-time. Unlike standalone vector indexes, which may demand a complete re-indexing process for new data inclusion, Pinecone facilitates immediate data integration. Its robustness, expansive scalability, and security features make it an optimal choice for real-time analysis in the cybersecurity sector, particularly for threat detection and cyberattack monitoring.
Backups and Collections: Pinecone effortlessly manages routine backup operations for all stored data. Moreover, it empowers users to selectively choose specific indexes for backup through "collections," allowing preservation of index-specific data for future use.
User-friendly API: Pinecone offers a user-friendly API layer that simplifies the development of high-performance vector search applications. This API layer is versatile in language integration, accommodating compatibility with any programming language.
Programming Language Integration: Pinecone supports a diverse range of programming languages for seamless integration.
Cost-effectiveness: Pinecone boasts a cost-effective advantage due to its cloud-native architecture, complemented by a pay-per-use pricing model.
Challenges
While Pinecone's vector database excels in high-performance data search at an elevated scale, it also faces certain challenges:
Application Integration: As with any evolving technology, application integration with other systems will evolve over time.
Data Privacy: Data privacy stands as a paramount concern for any database. Organizations must establish robust authentication and authorization mechanisms to ensure data security.
Interpretability of Vector-based Models: Vector-based models lack interpretability, posing challenges in understanding the underlying reasons behind relationships within the data.
Use Cases
Pinecone boasts a multitude of real-life industry applications, including:
Audio/Textual Search: Pinecone provides swift and deployable search and similarity functions for high-dimensional text and audio data.
Natural Language Processing: Leveraging AutoGPT, Pinecone constructs context-aware solutions for tasks such as document classification, semantic search, text summarization, sentiment analysis, and question-answering systems.
Recommendations: Pinecone facilitates personalized recommendations through efficient similar item suggestions, enhancing user satisfaction.
Image and Video Analysis: Pinecone excels in rapid retrieval of image and video content, proving invaluable in real-world applications like surveillance and image recognition.
Time Series Similarity Search: Pinecone's capability to detect time-series patterns within historical data is vital for applications like recommendations, clustering, and labeling.
Integrations
Pinecone seamlessly integrates with various systems and platforms, including Google Cloud Platform, Amazon Web Services (AWS), OpenAI's GPT models (GPT-3, GPT-3.5, GPT-4), ChatGPT Plus, Elasticsearch, Haystack, and more.
CHROMA:
Chroma is a company that develops an open-source project called Chroma, an AI-native open-source embedding database. Initially launched in 2021, Chroma is built upon the Faiss library, a widely used library for similarity search. Designed for ease of use and support for various applications, Chroma offers several advantages:
Fast Similarity Search: Chroma employs multiple techniques, including locality-sensitive hashing (LSH) and inverted indexes, to accelerate similarity searches. This makes it well-suited for applications demanding rapid similarity searches like recommendation systems, image search, and natural language processing.
Locality-Sensitive Hashing (LSH): LSH is an algorithmic method that hashes similar items into the same "buckets" with high probability.
Inverted Indexing: In an inverted index, the index is organized by terms (words), with each term linking to a list of documents or web pages containing that term.
Efficient Embedding Storage: Chroma uses techniques such as quantization and compression for efficient embedding storage. This is advantageous for applications requiring storage of large embedding datasets.
Scalability: Chroma scales effectively to handle large datasets, making it suitable for applications dealing with substantial embedding datasets.
Flexibility: Chroma offers flexibility, accommodating various applications by supporting multiple methods of storing and searching embeddings.
Challenges:
Limited Recognition: Chroma is less recognized compared to other vector databases like FAISS and Milvus. This lack of recognition can hinder finding adequate support and documentation.
Relative Newness: Being a relatively new project, Chroma might not be as mature as other vector databases, potentially leading to bugs or limitations.
Chroma's search logic is rooted in the Faiss library, which employs techniques like LSH and inverted indexes for speeding up similarity searches. These techniques help identify the most similar embeddings to a given embedding promptly.
Chroma differs from Pinecone in a few ways. Firstly, Chroma is open-source, offering accessibility and customization options for developers. Second, Chroma employs LSH for indexing, while Pinecone uses inverted indexes. As a result, Chroma is better suited for certain applications, while Pinecone excels in others.
In summary, Chroma is a potent tool for embedding storage and searches. It boasts speed, efficiency, scalability, and flexibility. However, it may not be as well-known or mature as other vector databases.
Comparison in Pinecone and Chroma:
| Feature | Chroma | Pinecone |
| Open source | Yes | No |
| Indexing Technique | LSH | Inverted Indexes |
| Cost | Free | Commercial |
| Best Suited For | Fast Similarity Search | High accuracy applications |
Weaviate:
Weaviate is an open-source vector database designed to offer efficient, scalable, and flexible solutions for storing and searching embeddings. Developed by Weaviate, it serves as a cloud-native, real-time vector database enabling the scaling of machine-learning models. Built upon the FAISS library – a widely recognized library for similarity search – Weaviate prioritizes user-friendliness and diverse application support.
- Foundation: Founded on July 11, 2019.
Here are some advantages of utilizing Weaviate:
Fast Similarity Search: Weaviate utilizes techniques such as locality-sensitive hashing (LSH) and inverted indexes to expedite similarity searches. This positions it well for applications requiring swift similarity searches, including recommendation systems, image search, and natural language processing.
Efficient Embedding Storage: Through quantization and compression among other techniques, Weaviate ensures efficient storage of embeddings, making it suitable for applications dealing with substantial embedding datasets.
Scalability: Weaviate accommodates large datasets effectively, making it a suitable choice for scenarios involving storage and retrieval of extensive embedding datasets.
Flexibility: Weaviate's adaptability enables its use across diverse applications due to its capability to store and search embeddings using various methods.
Challenges of employing Weaviate include:
Limited Recognition: Weaviate may not be as widely recognized as other vector databases like FAISS and Milvus, which can pose challenges in finding adequate support and documentation.
Relative Newness: Being a relatively recent project, Weaviate might not possess the same level of maturity as other well-established vector databases, potentially leading to bugs or limitations.
Weaviate's search logic is founded on the FAISS library, which employs techniques like LSH and inverted indexes to expedite similarity searches, aiding in the rapid identification of the most similar embeddings for a given query.
In contrast to Pinecone, Weaviate stands apart in several aspects. Firstly, Weaviate is open-source, allowing greater accessibility to developers and permitting customization to fulfill specific requirements. Additionally, Weaviate employs LSH as its indexing technique, diverging from Pinecone's use of inverted indexes. As a result, Weaviate might be better suited for certain applications, while Pinecone excels in others.
To sum up, Weaviate serves as a potent tool for embedding storage and searches, boasting speed, efficiency, scalability, and adaptability. However, it might not be as widely recognized as some other vector databases and might not have reached the same level of maturity.
Comparison in Weaviate and Pinecone:
| Feature | Weaviate | Pinecone |
| Open Source | yes | No |
| Indexing Technique | LSH | Inverted Indexes |
| Cost | Free | Commercial |
| Best Suited For | Fast Similarity Search | High Accuracy Applications |
FAISS a very special Vector Library:
FAISS:
FAISS (Facebook AI Similarity Search) stands as an open-source library specializing in efficient similarity search and clustering of dense vectors. Developed by the Facebook AI Research team, FAISS was initially introduced in 2016. It leverages a range of techniques, including locality-sensitive hashing (LSH), inverted indexes, and product quantization. FAISS is crafted to prioritize speed, efficiency, and scalability.
Here are some of the advantages of utilizing FAISS:
Fast Similarity Search: FAISS excels in rapid similarity searches, enabling the search through millions of vectors in mere milliseconds.
Efficient Storage of Embeddings: FAISS efficiently stores vector embeddings, a vital aspect since these embeddings can be substantial in size. This efficiency is crucial as storing such data in traditional relational databases might be inefficient.
Scalability: FAISS scales effectively to manage large datasets, catering to AI applications that often involve the storage and querying of expansive vector embedding datasets.
Flexibility: FAISS offers flexibility and versatility due to its ability to store and query vector embeddings using various methodologies.
Challenges of employing FAISS include:
Usability Complexity: FAISS can pose challenges for those unfamiliar with machine learning and database management, making it less user-friendly for beginners.
Limited Suitability for Complex Queries: While excelling in similarity search, FAISS might not be as well-suited for intricate queries compared to other vector databases better equipped for complex queries.
FAISS employs a blend of techniques, including LSH, inverted indexes, and product quantization, to facilitate its searching logic. These techniques enable the swift identification of the most similar vectors to a given query vector.
In comparison to Pinecone, FAISS distinguishes itself in several aspects. Firstly, FAISS is open-source, providing developers with greater accessibility and customization options. Secondly, FAISS employs LSH as its indexing technique, whereas Pinecone uses inverted indexes. As a result, FAISS might be better suited for certain applications, while Pinecone excels in others.
In summary, FAISS is a powerful library catering to similarity search and vector clustering, marked by its speed, efficiency, and scalability. However, it might be less familiar compared to some vector databases and might not be as well-suited for certain complex queries.
References: Medium official website blogs , documentations of databases mentioned in article, Blogs of Pinecone Senior Marketing manager :"GibbsCullen"